
I am currently working on my thesis for my master's. I am under the supervision of Professor Yves Lesperance and Professor Ruth Urner at York University. If you want further details, you can check my thesis proposal.Github Reposiroty
Abstract
This thesis will focus on improving two of the main concerns with reinforcement learning; safety and performance. When training an agent in an MDP the main focus is to maximize the cumulative reward it receives. Inherently, the exploration process typically does not concern itself with potential threats to the agent. Therefore, it can not guarantee its safety. Constrained Markov Decision Processes (CMDPs) are a special form of MDPs that allow for the separation of safety specifications from the reward function by naturally encoding the safety concerns as constraints. In a CMDP the goal is to learn an optimal policy that maximizes the cumulative reward while keeping the total safety cost under an established upper bound.
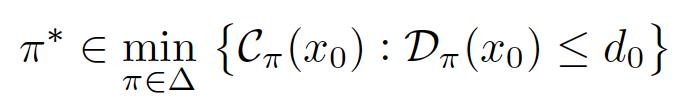
Another limitation has to do with intelligent agents not having access to the reward function governing their environment. For the agents, the reward function is a black box that provides an immediate reward given their current state and action. One way to approach this limitation is by introducing the use of logic to supply prior knowledge to the agent. Icarte et al. [2018a] introduced Reward Machines (RM), a particular form of finite state machines that provide an agent with access to the structure of the reward function.
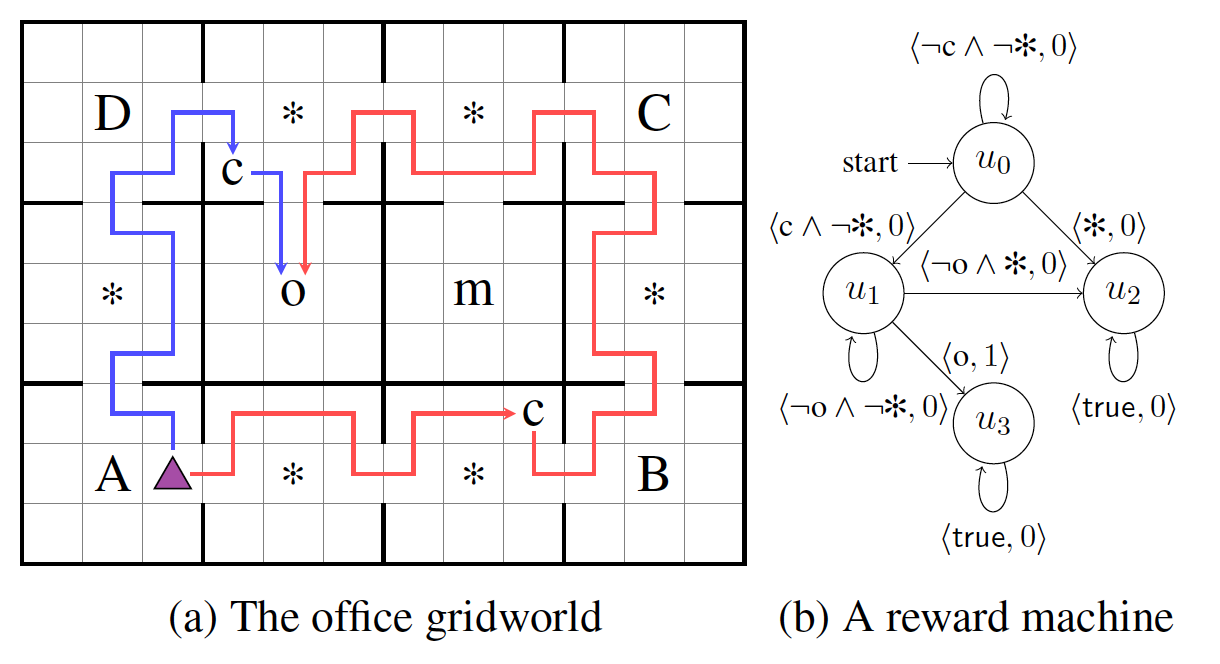
I am proposing the integration of Reward Machines with Constrained Markov Decision Processes. The goal is to develop a safer and more efficient solution to the constrained RL control problem. The idea is to use Linear Temporal Logic (LTL) to translate the reward functions into formal rewards and use it to construct an equivalent Reward Machine. I will be using the RM to transform the CMDP into a new framework called CMDP with a Reward Machine (CMDPRM). To solve the CMDPRM I will be developing a new algorithm called Constrained Learning for RM (CLRM) that will leverage the RM to achieve a faster and safer learning process. The goal is to test and evaluate the proposed methodology in the Safety Gym benchmark suite developed by Ray et al. [2019], which consists of high-dimensional continuous control environments meant to measure the performance and safety of agents in Constrained Markov Decision Processes.
