
This project was my introduction to RL and safe RL. I develop two grid-world simulations and an RL algorithm from scratch, with no ML or RL libraries, to experiment and test safety methods. For each simulation, the agent was capable of learning an optimal policy while staying safe. I developed this project during the last year of my undergraduate program, and it was the foundation to developing my Master's thesis. Github Reposiroty
An Introduction to Safe Reinforcement Learning
The use of Reinforcement Learning (RL) is becoming more widespread. With RL's rise in popularity, we have also seen a growing interest in studying the safety of RL algorithms. We want the learning agent to be safe during training and we want to ensure that the agent is safe to deploy. For example, we want to safely train an autonomous car and ensure that it won't be responsible for any accidents when deployed.
Safe Reinforcement learning has its complexities. Reinforcement learning is based on exploration and exploitation. How can an agent learn to be safe without experiencing unsafe scenarios? Furthermore, for some tasks, the threat of safety may be very infrequent. It is hard to ensure that training sets will include enough unsafe scenarios to ensure that safety-preserving behaviors are learned. Also, some reinforcement learning techniques construct their own representations of the domain (e.g., deep learning). It is hard to ensure that these representations carry the necessary information to ensure safety and that the resulting policies/strategies are safe.
Reading more about RL [1] and the work being done on safe RL [2] caught my interest. I thought it would be a good idea to develop some algorithms myself. For this project, I develop an RL algorithm and two grid-world simulations for testing purposes. Everything was developed from scratch, meaning that I didn't use any ML or RL libraries.
Both simulations involve 5x4 grids limited by four borders. The agent can move from one grid to another by performing 1 out of 4 possible actions (Up, Down, Left, and Right). The first set of grid-world environments are Navigation simulations. It consists of a planetary robot looking to travel from a starting point to a specified target destination while trying not to fall into craters.
The second set of grid-world environments are Mineral Collection simulations. It consists of a planetary robot looking to collect mineral ore and bringing it back to its starting position while trying not to fall into craters. The agent will automatically pick up the ore when it reaches its location.
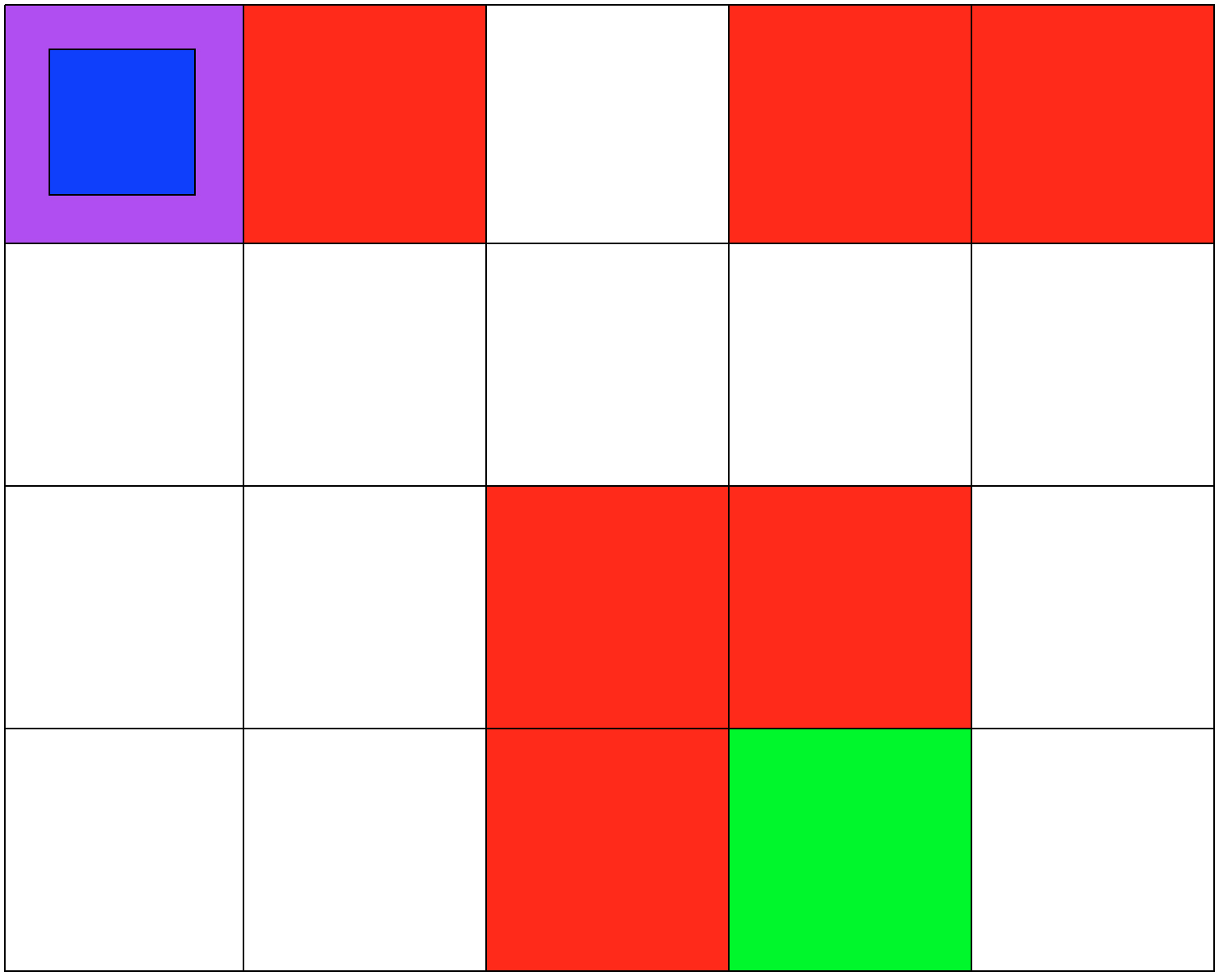
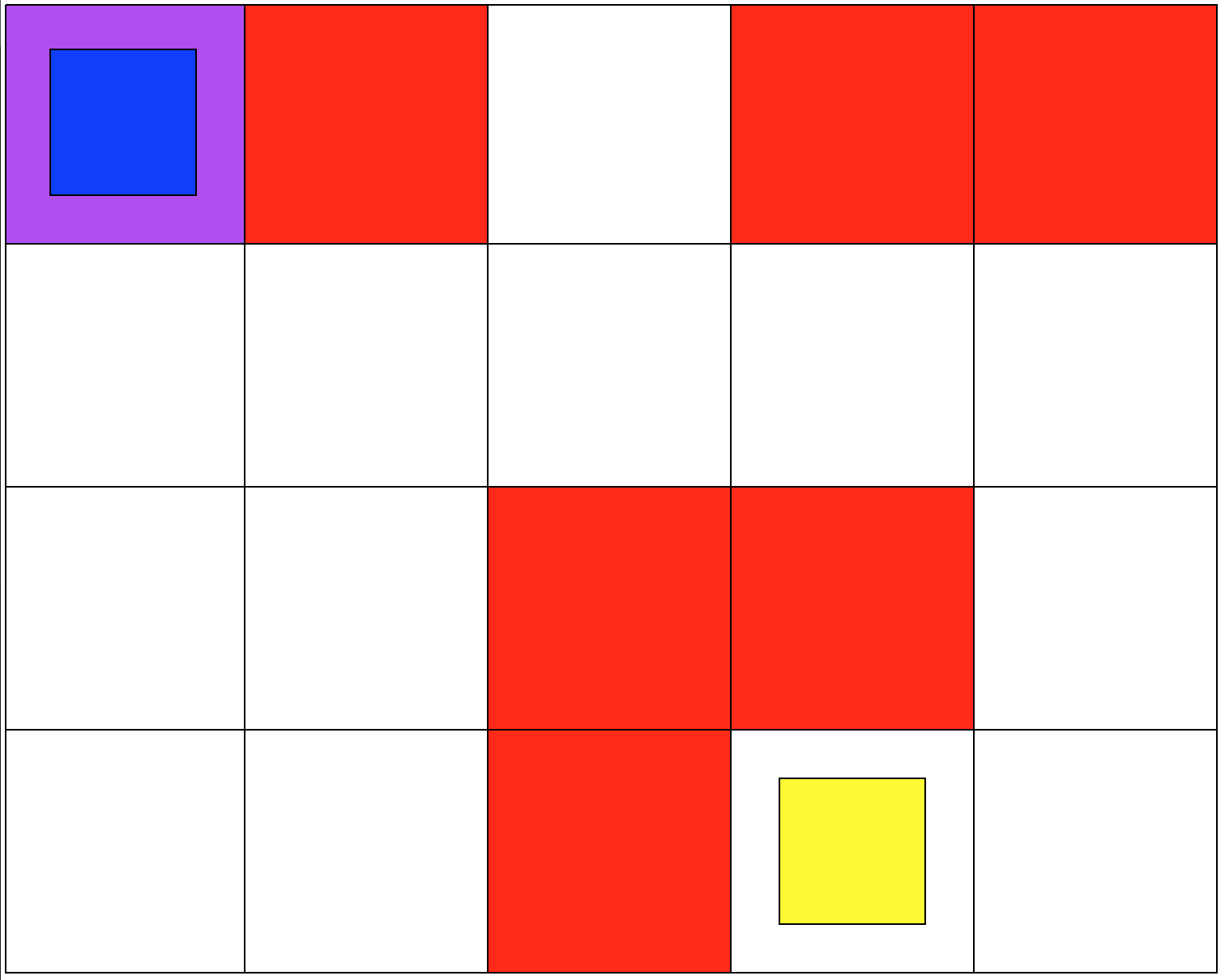
I implemented the Q-learning algorithm presented in Richard Sutton's textbook [1]. The Q-learning algorithm I developed is meant to solve any discrete RL problem. It only requires that the MDP has a finite set of states, a finite set of actions, a set of rewards, and a transition matrix.

I focused on making sure that the agent was capable of learning a policy that was safe to deploy. Specifically, to make sure that the agent will not fall into any crater on deployment. In our MDP the unsafe states will be represented as states that return negative rewards. I hypothesized that because the agent was trying to maximize cumulative reward it would try to avoid negative rewards. For both simulations, the craters have a negative reward, and the target destination has a positive reward. All other states have a reward of 0. In the Mineral Collection environment picking up the mineral ore also has a positive reward.
After developing, training, and deploying the agents I was able to achieve my goal. For every iteration of the Navigation and Mineral Collection environments, the agents learned an optimal and safe policy. The key was to test different values for the rewards, and parameter tuning the Q-learning algorithm. If the punishment was set too high, the agent would focus on not falling and would avoid its actual goal, or it would learn a non-optimal policy. If the reward was too high the agent would ignore the craters and the resulting policy would be unsafe.
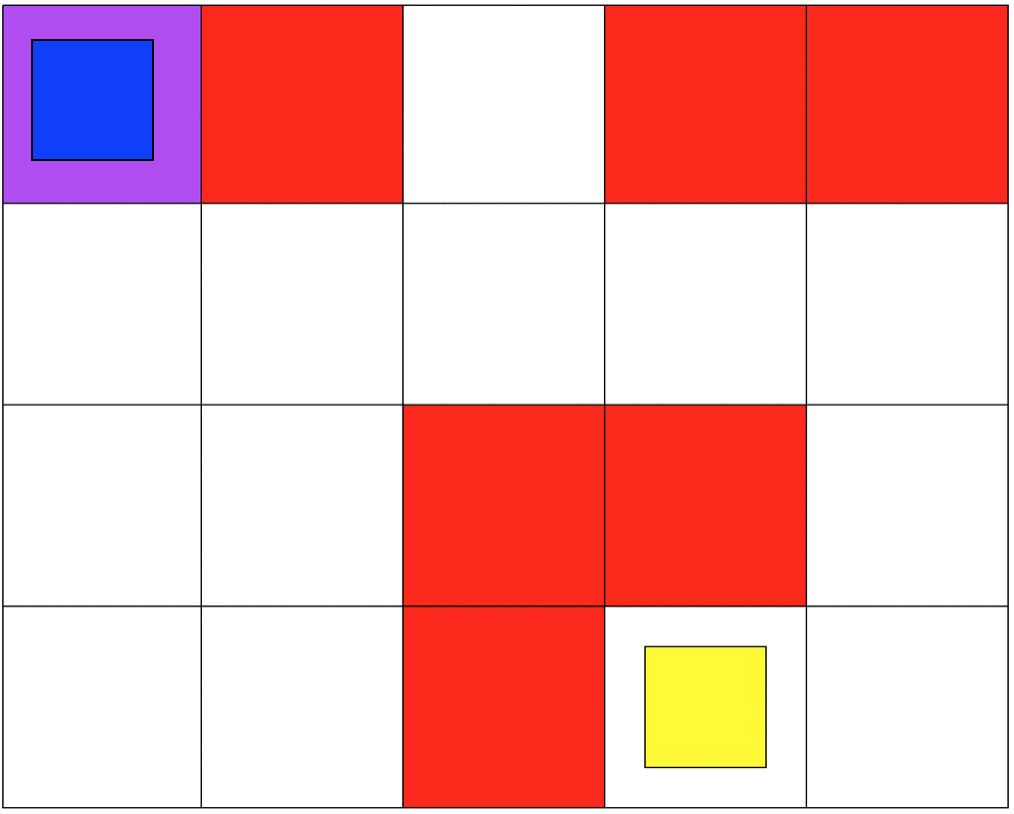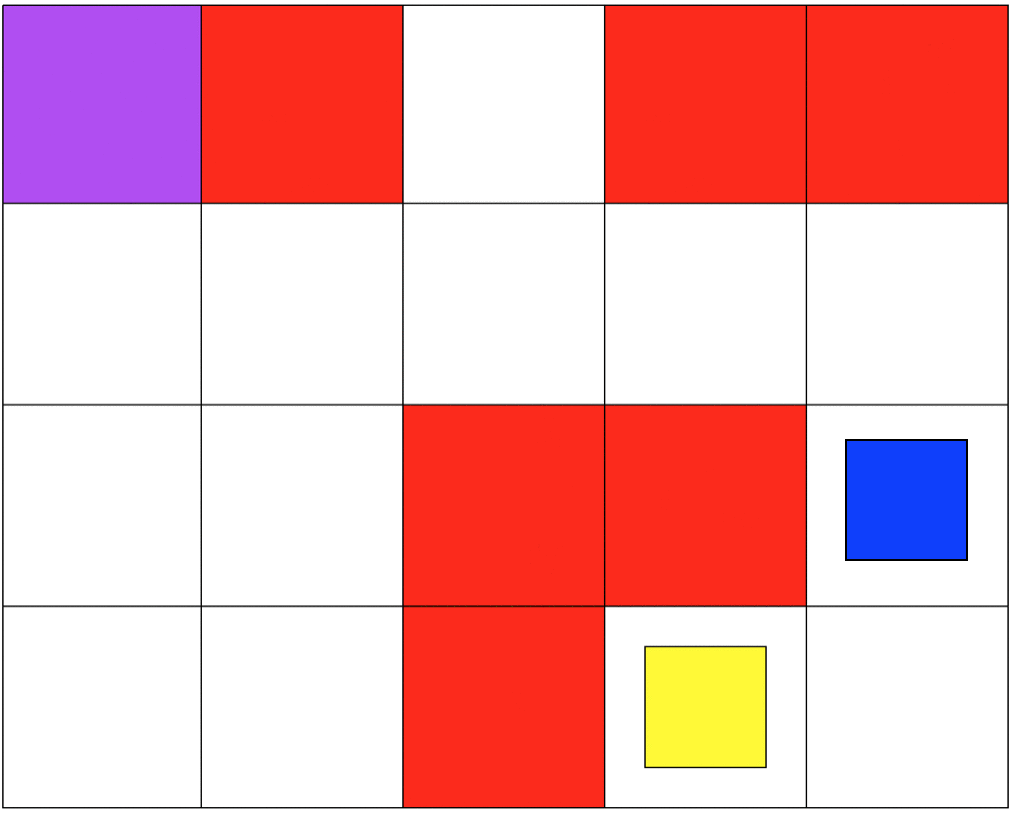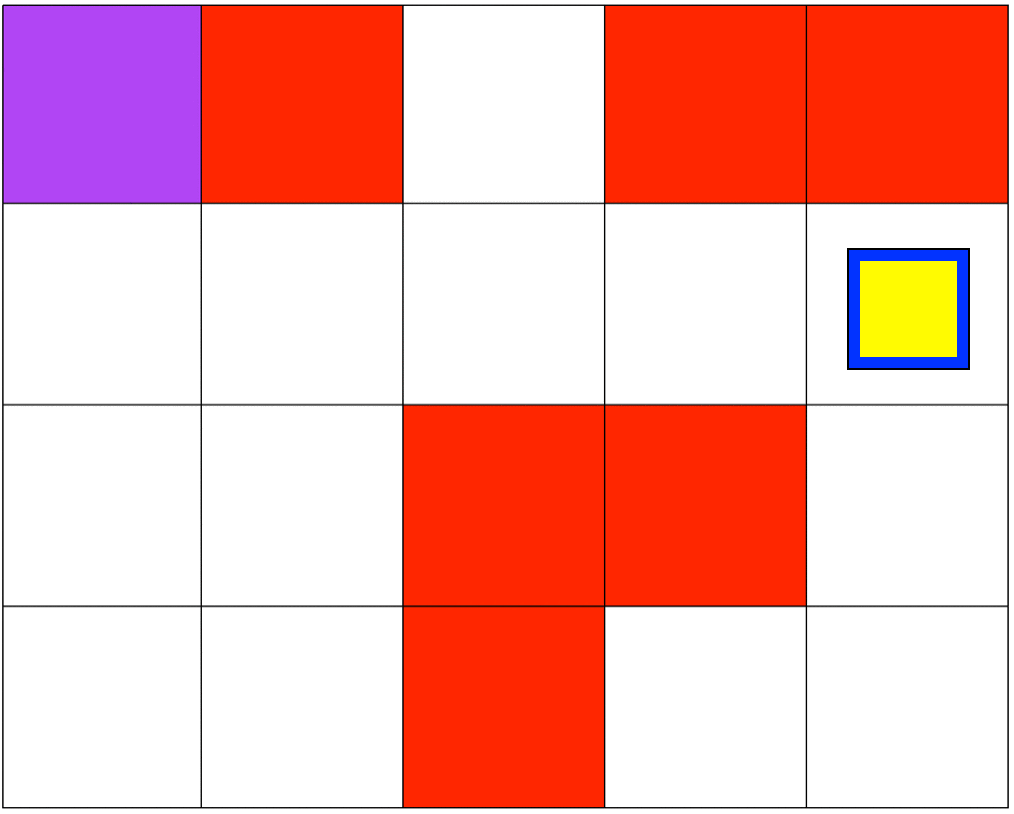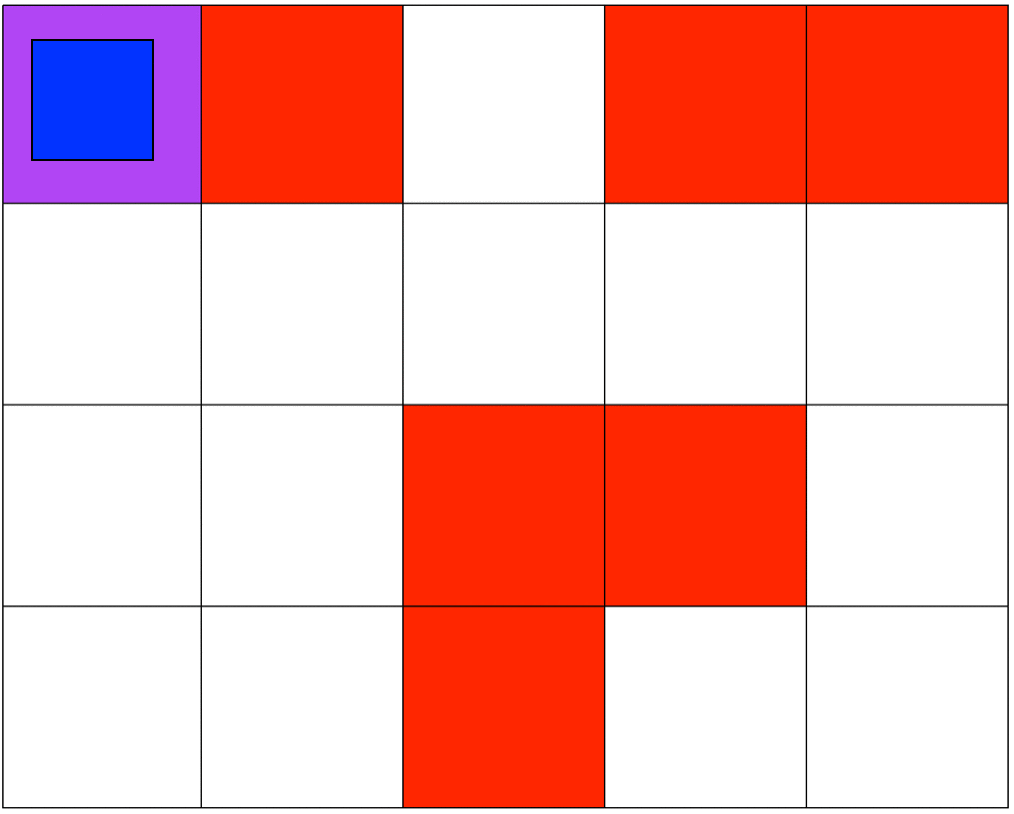
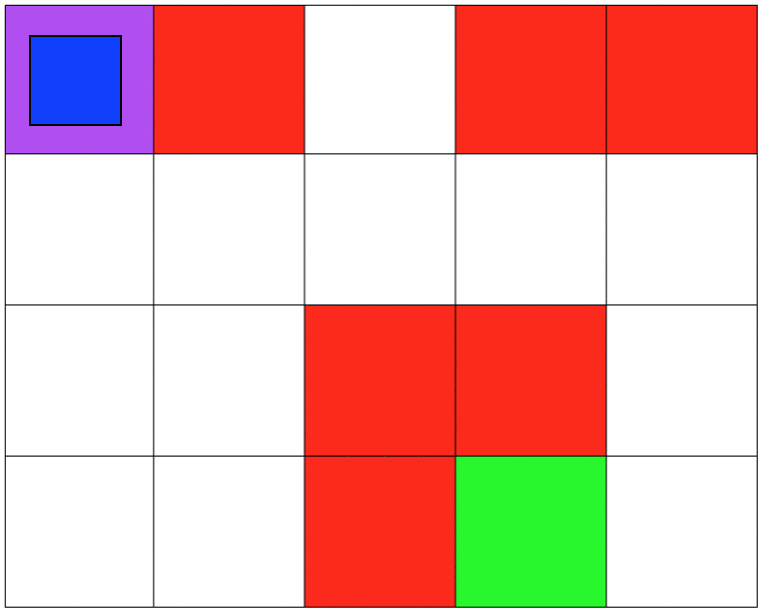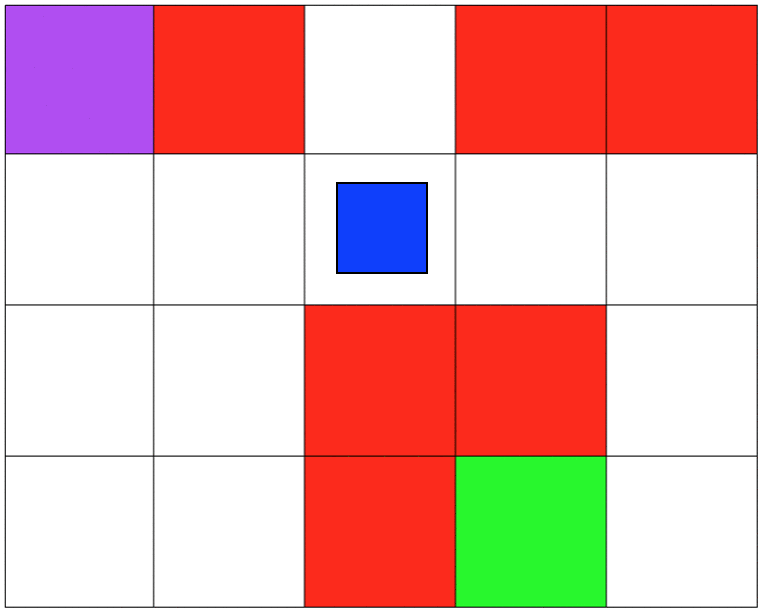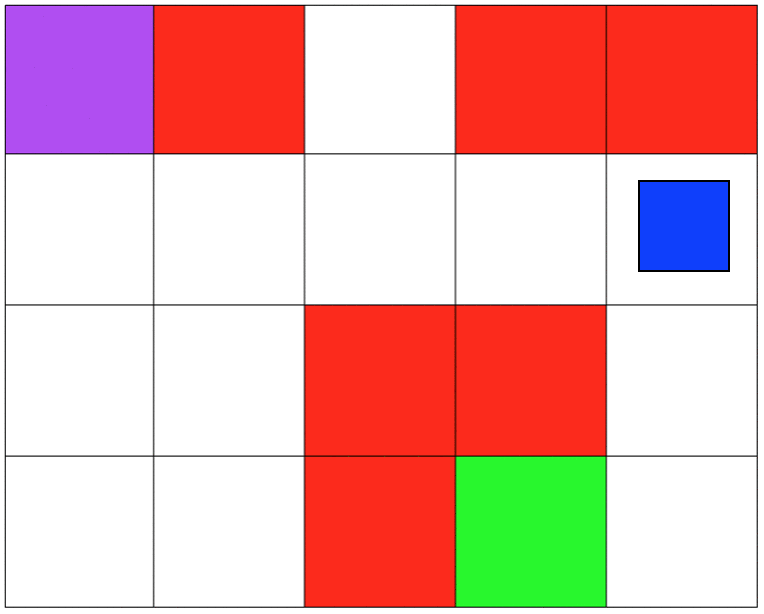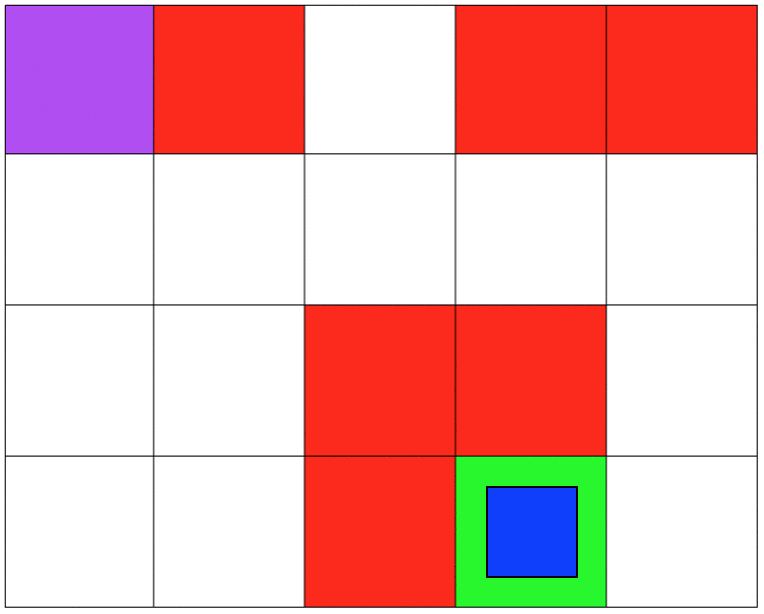
Even though my approach works, it had a lot to do with manually tunning several parameters to succeed. As mentioned earlier, this project is my introduction to Reinforcement Learning and Safe RL. Currently, my work focuses on more complex safety strategies and the agent's safety during training.